Mom-We-have-Autoencoder-at-home
Mom: We have Autoencoder at home
This is repo for Silly Dimensional Reduction where we use PCA to reduce the dimension of the data, then later on use the multiple multivariate linear regression to recreate the initial image like what Autoencoder do. This is a class project for MA 554 Applied Multivariate Analysis at WPI I did in a span of a week (so, it is not well-refined nor that deep in terms of mathematics).
Rationale
I hate when people say autoencoder is a neural network. Given the data $x \in \mathbb{R}^{m}$, we can potentially summarize that data down into an embedding $q \in \mathbb{R}^{k}$ for $k « m$. This is essentially an encoder part of an autoencoder. Now, we just need the decoder part. The naive model to do this is a regression model $f:\mathbb{R}^{k} \rightarrow \mathbb{R}^m$. Now, if we just do it with only PCA and least square linear regression, the model (as proved mathematically in the slide) will only span on the PC score’s space. So, this work also try the expand that idea on treating the parameters for the regression as random variable (essentially, do a Bayesian regression) that algebraically linear but might not collapse into one projection mapping. That Bayesian regression is optimized by using variational inference to make it akin to the VAE.
Result
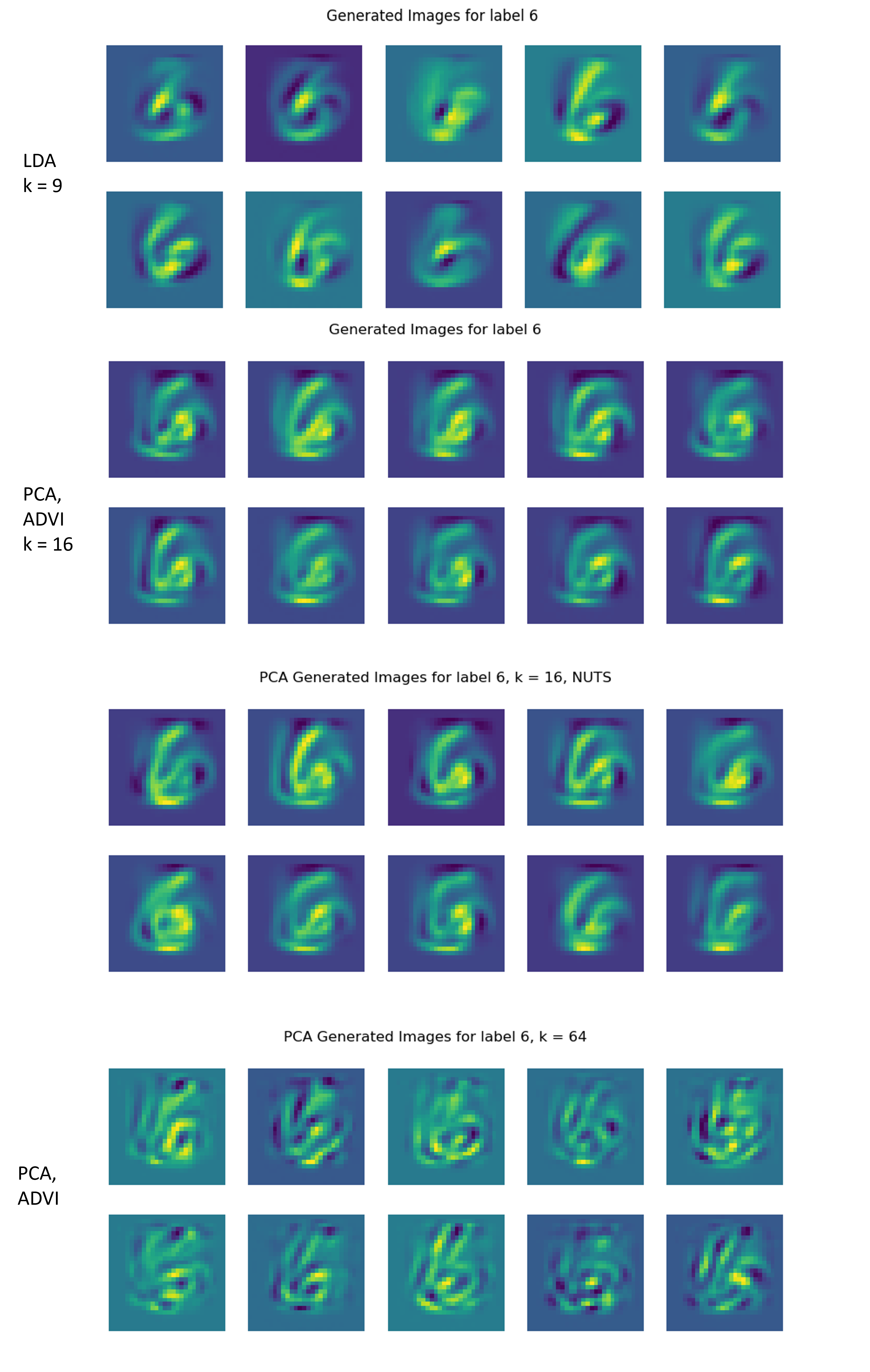
Here is an empirical result, the MSE is around 0.01 on 25% test set of the linear regression model so it is quite working well. Note that the second image is used with non-linear model (kernel regression with RBF kernel, because I want to see one of my point in the discussion)


More result (including mathematical derivation and more result) can be viewed on my slide. Here, only VI is explored because (from my perspective) ML community usually try the fast to implement and computationally less expensive option. However, I also try the MCMC method (as this is Bayesian linear regression afterall) and got the similar result.
MCMC (NUTS)
Here, the result of MCMC is denoted by NUTS and the VI method is denoted by ADVI. It does not look that nice compared to the slide result as those in the slide is passed through the thresholding function.